# 集合概述
集合类又称容器类,主要用于保存数据。
# 常用方法
Collection 接口中有以下方法:
| 方法 | 说明 |
|---|---|
| add(Object obj) | 向集合中添加指定元素 |
| remove(Object obj) | 从集合中删除指定元素 |
| clear() | 清空集合所有元素 |
| contains(Object obj) | 判断集合中是否有指定元素 |
| isEmpty() | 判断集合是否为空 |
| iterator() | 返回一个 Iterator 对象,用于遍历集合 |
| size() | 返回集合的元素个数 |
| toArray() | 将集合以数组形式返回 |
# 集合类与数组的区别
- 数组:
- 长度固定
- 元素既可以是基本类型,也可以是引用类型
- 只能存储同一类型的数据
- 集合类:
- 长度可变
- 元素仅能是引用类型(的指针)
- 可以存储不同类型数据
# 集合的分类
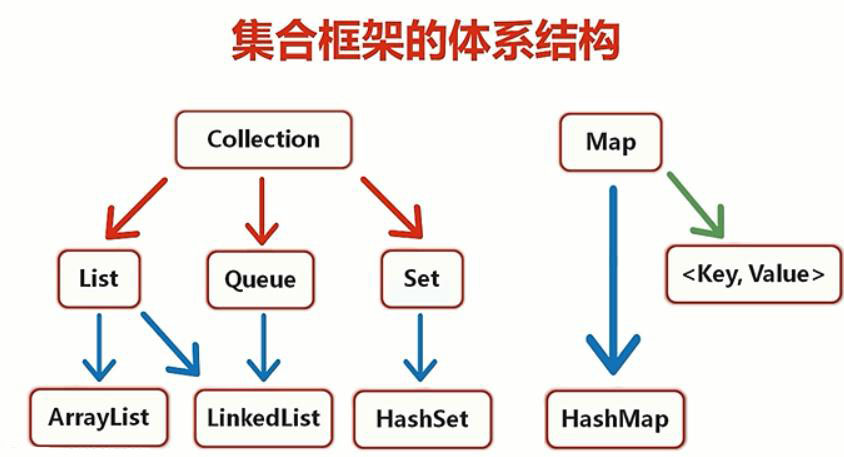 集合可以分为两大类:
集合可以分为两大类:
- Collection:用于存储数量不等的数据
由 Collection 派生出的集合类有:- List:有序、可重复的集合
- Set:无序、不可重复的集合
- Queue:队列
- Map:用于储存一组键值对
# 集合的遍历
# foreach
foreach (元素类型 temp : 集合) {
···
}
2
3
# 遍历器
Iterator 用于遍历集合中的元素,又称为遍历器。
方法
| 方法 | 说明 |
|---|---|
| hasNext() | 判断是否有下一个元素 |
| next() | 返回集合中下一个元素 |
| remove() | 删除上一个 next() 返回的元素 |
| forEachRemaining(Consumer action) | 用 Lambda 表达式遍历集合 |
示例
Iterator iterator = 集合名.iterator();
while (iterator.hasNext()) {
···iterator.next()···
}
2
3
4
# Set
提示
Set 用于储存一组唯一的、无序的对象
# HashSet
通过 hash 算法来存储元素。
特点
- 遍历顺序与存储顺序无关
- 元素可以是 null
- 不是线程安全的,如果有多个线程同时访问,最终结果是不确定的
# LinkedHashSet
LinkedHashSet 是 HashSet 的子类,它也是通过 hash 算法来存储元素,但还同时使用链表维护元素的次序。
特点
- 遍历顺序是存储顺序
- 性能略低于 HashSet
- 遍历时具有更好的性能
# TreeSet
TreeSet 采用红黑树的数据结构来存储集合元素。
TreeSet 可以确保元素处于排序状态,并且此排序状态与元素的存储顺序无关,根据元素值进行排序。
特点
- 元素会处于排序状态
- 为保证元素之间可比较,应向 TreeSet 中添加同类元素
- TreeSet 支持两种排序方法
- 自然排序
- 定制排序
# EnumSet
EnumSet 是专门用于存取枚举的集合类,其中所有元素必须是指定枚举类型的枚举值。
特点
- 集合有序,以枚举类中的顺序排序
- 不允许加入 null 元素
- 所有元素必须是指定枚举类中的元素
# List
提示
List 用于储存一组可重复的、有序的对象
# 常用方法
| 方法 | 说明 |
|---|---|
| add(index, obj) | 将元素插入到 index 处 |
| addAll(index, collection) | 将集合中所有元素插入到 index 处 |
| get(index) | 返回 index 处的元素 |
| indexOf(obj) | 返回元素在集合中第一次出现的位置 |
| lastIndexOf(obj) | 返回元素在集合中最后一次出现的位置 |
| remove(index) | 删除并返回 index 处的元素 |
| set(index, obj) | 将 index 处的元素替换为指定元素 |
| subList(fromIndex, toIndex) | 返回从 fromIndex 到 toIndex 的所有元素组成的子集 |
| replaceAll(UnaryOperator operator) | 根据 operator 指定的计算规则重新设置集合中所有的元素 |
| sort(Comparator comparator) | 根据 comparator 对集合中元素进行排序 |
# 遍历器特有方法
| 方法 | 说明 |
|---|---|
| hasPrevious() | 是否有上一个元素 |
| previous() | 返回上一个元素 |
| add(obj) | 插入元素 |
# ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别在于没有固定大小的限制,可以添加或删除元素。
常用方法
| 方法 | 说明 |
|---|---|
| add(obj) | 添加元素 |
| get(index) | 访问元素 |
| set(index, obj) | 修改指定索引值处的元素 |
| remove(obj) | 删除指定元素 |
| remove(index) | 删除指定索引位置的元素 |
| size() | 获取元素个数 |
语法格式
// 引入ArrayList类
import java.util.ArrayList;
// 初始化
ArrayList<泛型数据类型> 集合名 =new ArrayList<>();
2
3
4
其中,泛型数据类型用于设置 ArrayList 对象的数据类型,只能为引用数据类型。
ArrayList 和 Vector
主要区别有:
- Vetor 较为古老,因此存在一些功能相同但是方法名更长的方法
- ArrayList 是线程不安全的; Vector 是线程安全的
- ArrayList 性能更好; Vector 性能较低
- Vector 提供了 Stack 子类,用于模拟栈
# LinkedList
LinkedList 是基于链表的 List 实现类。
Deque 实现
LinkedList 实现了 Queue 的子接口 Deque,它将实现 Deque 中的方法,这意味着它可以当作队列、双端队列、栈使用。
ArrayList 和 LinkedList
- ArrayList 增、删效率高 LinkedList 改、查、遍历效率高
- 以下情况使用 ArrayList :
- 频繁访问集合中的某一个元素
- 只需要在集合末尾增、删元素
- 以下情况使用 LinkedList :
- 需要遍历集合
- 需要频繁增、删元素
# Queue
提示
Queue 以队列的形式存储元素
# 常用方法
| 方法 | 说明 |
|---|---|
| add(obj) | 添加元素至队尾 |
| remove() | 移除队头元素 |
| element() | 返回队头元素 |
| peek() | 返回队头元素 |
| poll() | 返回并删除队头元素 |
| offer() | 添加元素至队尾 |
# PriorityQueue
- PriorityQueue 并不是一个标准的队列实现列
- 并不是以加入队列的顺序为依据进行排序,而是按队列元素的大小进行排序
- 可以使用自然排序,也可以使用定制排序
提示
自然排序和定制排序具体可以参照上文
# ArrayDeque
ArrayDeque 是基于数组实现的双端队列,它可以当作队列、双端队列、栈使用。
umElements
在创建 ArrayDeque 时可以指定 numElements 参数,该参数用于指定数组的长度,如果不指定,则数组默认为 16 。
LinkedList
LinkedList 同样实现了 Deque 接口,因此也可以当作队列、双端队列、栈使用。
# Map
提示
Map 用于储存一组键值对
# 常用方法
| 方法 | 说明 |
|---|---|
| put(key, value) | 添加元素 |
| remove(key) | 根据 key 删除元素 |
| get(key) | 根据 key 获取元素 |
| containsKey(key) | 判断集合中是否有指定的 key |
| containsValue(value) | 判断集合中是否有指定的 value |
| keySet() | 返回所有 key 组成的 Set |
| values() | 返回所有 value 组成的 Set |
| entrySet() | 返回所有键值对组成的集合 |
# entrySet()
该方法将会返回所有键值对组成的集合。
其中,键值对以 Map.Entry 对象的形式保存。
提示
Map 的内部类 Entry 的实例
Map.Entry 包含以下方法:
| 方法 | 说明 |
|---|---|
| getKey() | 获得对象中的 key |
| getValue() | 获得对象中的 value |
- key 不能重复 value 可以重复
- 作为 key 的类应该重写判断对象是否相等的方法,以保证符合逻辑上的“相等”与“不等”
- 如果添加的键值对中键发生重复,则先添加的键值对会被覆盖
# HashMap
通过 hash 实现的 Map 。
HashMap 和 Hashtable
- Hashtable 更古老
- HashMap 是线程不安全的 Hashtable 是线程安全的
- HashMap 的性能略高
- HashMap 允许 key 和 value 为 null
提示
但只能有一个 key 为 null Hashtable 不允许 null
# LinkedHashMap
提示
与 LinkedHashSet 类似,HashMap 也有一个名为 LinkedHashMap 的子类
LinkedHashMap 是 HashMap 的子类,它也是通过 hash 算法来存储键值对,但还同时使用链表维护键值对的次序。
特点
- 遍历顺序即是存储顺序
- 性能略低于 HashSet
- 遍历时具有更好的性能
# EnumMap
EnumMap 是与枚举类一同使用的 Map,其中所有 key 必须是指定枚举类型的枚举值,创建 EnumMap 时必须指定枚举类。
特点
- 集合有序,以枚举类中的顺序排序
- 不允许加入 null 元素
- 所有 key 必须是指定枚举类中的元素
# Collections
Collections 是一个用于操作 Set、List、Map 等集合的工具类,该工具类中提供了对于集合的操作方法。
# 对 List 的方法
| 方法 | 说明 |
|---|---|
| reverse(list) | 反转 list 中元素的顺序 |
| shuffle(list) | 对 list 中的元素进行随机排序 |
| sort(list[, comparator]) | 对 list 进行自然排序或指定排序 |
| swap(List, index1, index2) | 将 list 中 index1 和 index2 的元素进行交换 |
| rotate(list, distance) | 当 distance 为正时,将后 distance 个元素移到前面;当 distance 为负时,将前 distance 个元素移到后面 |
| binarySearch(list, obj) | 用二分法查找指定元素,要求 list 有序 |
| fill(list, obj) | 用指定元素填满 list |
| indexOfSubList(list, subList) | 返回 subList 在 list 中第一次出现的位置 |
| lastIndexOfSubList(list, subList) | 返回 subList 在 list 中最后一次出现的位置 |
| replaceAll(list, oldVal, newVal) | 用 newVal 替换 list 中的 oldVal |
# 对 Collections 的方法
| 方法 | 说明 |
|---|---|
| max(collection[, comparator]) | 根据自然排序或指定排序,返回 collection 中的最大元素 |
| min(collection[, comparator]) | 根据自然排序或指定排序,返回 collection 中的最小元素 |
| frequency(collection, obj) | 返回 obj 在 collection 中的出现次数 |
# synchronizedXxx()
Collections 类中提供了多个 synchronizedXxx() 方法,用于将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。
Xxx 集合名 = Collections.synchronizedXxx(非同步集合);
public class Test {
public static void main(String[] args) {
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());
}
}
2
3
4
5
6
7
JAVA 9 新增
可以通过类方法 of(obj, obj, ···, obj) 创建具有若干个指定元素的不可变集合。
Xxx 集合名 = Xxx.of(obj, obj, ···, obj);
List list = List.of(obj, obj, ···, obj);
Set set = Set.of(obj, obj, ···, obj);
Map map = Map.of(obj, obj, ···, obj);
2
3
# Stream 流
# 什么是 Stream 流?
Stream 流是 JAVA8 中添加了一个新的接口类,相当于高级版的 Iterator。
Stream 流将元素集合看作一种流,通过一系列处理得到最终的结果。
# 创建 Stream 流
直接创建
创建 Stream 的 builder,再通过 add() 方法增加元素,最后调用 build() 方法创建 Stream 流。
Stream.builder().add(元素).add(元素) ··· .add(元素).build()
通过 Collection 创建
Collection实例.stream()
通过 Map 创建
首先通过 Map 的方法获得 Collection实例,然后再创建 Stream 流。
// 所有key组成的集合
Map实例.keySet().stream()
// 所有value组成的集合
Map实例.values().stream()
// 所有键值对组成的集合
Map实例.entrySet().stream()
2
3
4
5
6
通过数组创建
通过 Stream 的静态方法 of() 创建
Stream.of(数组)
处理 Stream 流
| 方法 | 说明 |
|---|---|
| filter(Predicate predicate) | 过滤所有不符合 predicate 的元素 |
| limit(long maxSize) | 只保留前 maxSize 个元素 |
| skip(long discardNum) | 丢弃前 discardNum 个元素 |
| concat(Stream stream1, Stream stream2) | 合并 stream1 和 stream2 |
| distinct() | 过滤,相同的元素只保留一个 |
| sorted([Comparator comparator]) | 排序,自然排序或通过 comparator 排序 |
| map(Function function) | 返回将 function 应用于每个元素之后的 Stream 流 |
# 终结 Steam 流
调用以下方法后,Stream 流将终结。
| 方法 | 说明 |
|---|---|
| foreach(Consumer consumer) | 遍历元素,对每个元素执行 consumer |
| toArray() | 转换为数组 |
| count() | 返回流中的元素个数 |
示例
public class Student {
private String name;
private int score;
// 构造方法
// get方法
// equals()和hashCode()
// toString()方法
}
public class Test {
public static void main(String[] args) {
ArrayList<Student> arrayList = new ArrayList<>();
arrayList.add(new Student("小王", 100));
arrayList.add(new Student("小王", 100));
arrayList.add(new Student("小王", 100));
arrayList.add(new Student("小李", 94));
arrayList.add(new Student("小张", 97));
arrayList.add(new Student("小笨", 60));
arrayList.add(new Student("小坏", 0));
arrayList.stream()
.filter((Student student) -> student.getScore() >= 60)
.distinct()
.forEach(System.out::println);
}
}
// 运行结果
Student{name='小玉',score=100}
Student{name='小李',score=94}
Student{name='小张',score=97}
Student{name='小笨',score=60}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33